-
mongoDB 튜토리얼 7. 샤딩DB/MongoDB 정리 2019. 11. 26. 10:38
데이터베이스 파티셔닝
- 데이터베이스를 분리하여 여러 서버에 분산 저장 및 관리하는 기술
1. 수직 파티셔닝
- 하나의 테이블이 너무 커서 하나의 서버에 유지할 수 없을 때
R(A1, A2, A3 | A4, A5)
R1(A1, A2, A3, A4) R2(A1, A5)
ex) 패턴을 분석하여 관련되게 검색되는 에트리 뷰트를 주로 한 묶음으로 한다. R1 테이블만 써서 질의를 해결할 수 있다.
-RDB에서 많이 사용하는 방법
2. 수평 파티셔닝 ( = 샤딩 )
-로우(문서) 별로 데이터베이스를 분할하는 방법
ex) 월 별로 문서 집합을 따로 분리
1월 로우들을 한 DB에 2월 로우들을 한 DB에...

이렇게 분할된 데이터 SET을 샤드라고 한다. 샤드(shard)는 조각을 뜻한다.
단일 머신에서는 데이터를 저장하는데 충분치 않거나, read write 성능이 한 머신에 몰리게 될 수 있는데
몽고 DB는 수평적 파티션 방식으로 이러한 문제를 해결한다.
데이터가 월별로 데이터 셋이 분할돼서 저장됐다고 하였다.
예를 들면 샤드가 2개라면 1~6월은 첫 샤드에 7~12월은 두 번째 샤드에 놓는 것이다.
이때 replica set으로 구성돼있는데 이 샤드들은 디스크 하나 짜리가 아니라 복제 셋 기술을 이용해서 여러 카피를
또 가지게 된다. 즉 복제기술과 샤드를 섞는 것.
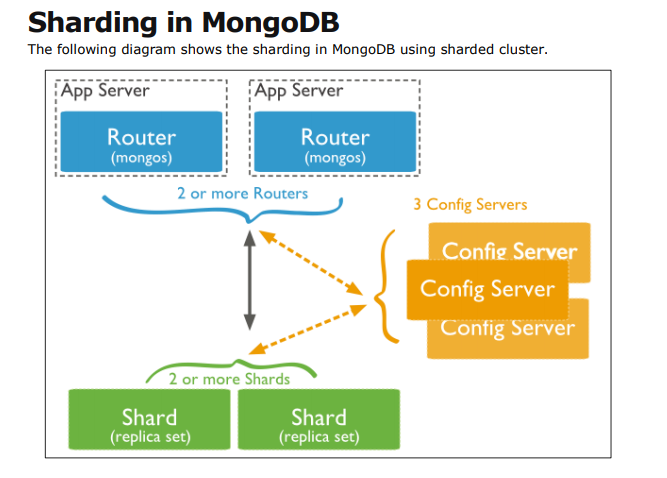
non - sharding vs sharding
client에게는 데이터가 분산되었는지 아닌지 알 수 없어야 한다. 즉 분산된 형태를 알 필요도 볼 필요도 없어야 한다. => 투명성
client가 질의를 날리면 mongos 가 어느 샤드에 데이터가 있는지 찾아주고 조회해서 보여준다.
이런 mongos가 위에 나온 Router인데 쉽게 말하면 길을 찾아주는 역할을 한다고 보면 된다.
이런 Router역할을 하는 mongoDB에 프로그램이 mongos이다.
몽구스역시 사용자가 몰릴 경우를 대비해 2개 이상을 쓰는 것.
Config Server는 환경에 대한 데이터를 가지는데 어느 샤드에 1월 데이터가 있고 12월 데이터가 있는지 알고 있다.
즉 어떻게 데이터가 분할되는지에 대한 환경 설정 메타데이터들이 들어있고 하나가 깨져도 계속해서 유지할 수 있도록
여러 개로 돼있다. 또 메타데이터의 일부를 몽구스와 공유한다.
Sharding
Shards : Sharded data의 일부를 가지고 있고 레플리카 셋으로 구현할 수 있으며 따로따로 구현해 주어야 한다.
Config servers : 환경설정에 대한 데이터를 영구적으로 디스크에 저장한다. 샤드 설정들에 대한 원천 데이터.
Routers : 몽구스 역시 config servers의 데이터 일부를 캐시 형태로 가지고 있다. 어느 샤드로 들어가야 하는지
알려준다.
Why Sharding?
- In replication, all writes go to master node
- Latency sensitive queries still go to master
- Single replica set has limitation of 12 nodes
- Memory can't be large enough when active dataset is big
- Local disk is not big enough
- Vertical scaling is too expensive
샤드 키(Shard keys)
-특정 필드를 기준으로 문서를 여러 샤드에 분산하는데 샤드 키는 분산할 때의 기준 필드를 말한다.
두 개 이상의 필드를 묶어서 기준을 삼을 수도 있다. ( 년, 월 기준으로 샤딩)
청크( chunks)
-샤드안에 들어있는 더 작은 단위. 샤드 키값에 따라 연속적인 범위를 갖는다.
한 샤드안에 여러 개 청크를 나눈다.
고른 청크 분포
-매출 데이터중 1~3월에 매출이 다 일어난다면 그 샤드에만 질의가 몰릴 것이다. 이렇듯 한쪽에만 데이터가 몰릴 수
있기 때문에 그 샤드안에 청크를 다른 샤드들에게 분포한다.
샤딩의 장점
읽기 및 쓰기
- 데이터가 늘어나도 샤드를 더 붙이면 된다. 질의가 들어올 때 질의 조건에 샤드 키로 사용된 필드가
들어온다면 몽구스가 질의를 특정 샤드로 라우팅을 해줄 수 있다.
(질의 분석을 통해 가장 효과적인 것을 샤드키로 해야 한다.)
저장 용량
- 데이터가 늘어나도 샤드를 추가해도 클러스터의 저장 기능을 유지할 수 있다.
고가용성
- 한 샤드가 죽어도 나머지 샤드들이 살아있기에 서비스는 계속되고 복 제 셋으로 구성되기에 auto failover이 들어간다. config servers 역시 최소 3개 이상 돌리고 역시 replica set으로 구성해야 한다.

한 컬렉션 안에는 샤드 방식으로 분할할 수 있고 분할하지 않을 수도 있다. 양이 작다던지 등..
이렇게 혼합 형태로 구성 가능. 샤드 단위가 컬렉션 단위로 가능하다.

Read Write는 몽구스 라우터가 질의를 어디로 보낼지 결정한다. 컬렉션 1의 질의는 질의에 샤드 키가 없다면 샤드 A , B에 다 질의 요청을 해야 한다.
라우터인 몽구스는 컬렉션 2는 샤드가 되지 않았다는 걸 알고 있고 컬렉션 2의 질의는 샤드 A 쪽에만 라우팅을 해줘서 데이터를 처리하게 한다.
샤딩은 Ranged 샤딩과 Hash 샤딩으로 구분할 수 있다.

1) Ranged Sharding
- 앞서 배운 1~6월과 같이 범위로 자른 샤딩이다. 한 샤딩은 청크로 나누어져 있는 것을 알 수 있다.
Ranged Sharding에 효율성은 샤딩키에 달려있다.
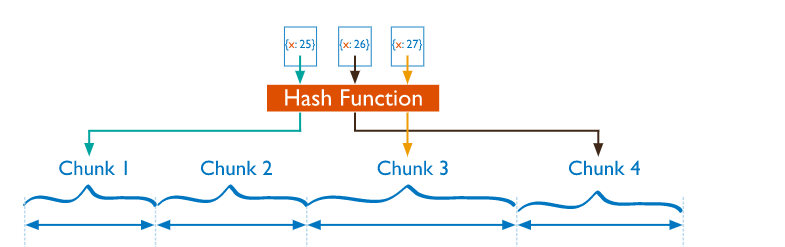
2) Hashed Sharding
Ranged 샤딩같은 경우 위에 샤드 키 값 셋(3)은 값이 비슷하니 같은 샤딩에 들어갈 가능성이 있지만 해시 function은 전
혀 상관없고 샤드 키에 해쉬 function을 한번 더 돌려서 나온 해쉬값을 기준으로 분산시킨다.
해쉬 function에서 나온 결과 위에 샤드 키값 셋의 값은 전혀 close하지 않고 다른 chunk에 분산된 것.
즉 Hash값을 기준으로의 분산은 고른 데이터 분산에 훨씬 용이하다. 특히 선형적으로 변하는 샤드 키들
ex) 각 학생마다 취미가 다 다르면 취미로 ranged sharding 해서는 안된다. 각 샤드당 학생 한 명만 들어있기 때문
이럴 때는 취미를 기준으로 해쉬에다 넣는다면 만 명에 학생이 대해서 축구, 배구, 야구가 샤드 1에 담길 수 있다.
즉 그룹화하기에 적합지 않다면 그런데 샤드를 해야 한다면 사용. Ranged sharding보다 훨씬 고른 분산이 가능하다.
간단히 router 1개 ( mongos) 샤드 2개 (mongod) config server (mongod - 메타데이터 이기때문) 1개로 sharding을 구현해보자.

( replicaSet은 shard 1 하나의 복제를 만든 것? )
복제세트를 충분히 연습하고 샤딩에 도전하자
'DB > MongoDB 정리' 카테고리의 다른 글
mongoDB 튜토리얼 8 - DBRefs (0) 2019.12.03 mongoDB 튜토리얼 6. 레플리카 셋 (0) 2019.11.19 MongoDB 튜토리얼 5. Aggregation (0) 2019.10.15 MongoDB 튜토리얼 4. CRUD (31) 2019.10.01 MongoDB 튜토리얼 3. CRUD (31) 2019.09.24