-
mongoDB 튜토리얼 8 - DBRefsDB/MongoDB 정리 2019. 12. 3. 10:45
Relationships in MongoDB represent how various documents are logically related to each other. Relationships can be modeled via Embedded and Referenced approaches. Such relationships can be either 1:1, 1:N, N:1 or N:N.
몽고 디비 역시 두 개의 문서를 서로 떨어뜨려서 참조 방식으로도 표현할 수 있다.
문서 하나로 유저 정보하고 주소 정보들을 하나로 묶어서 표현하는 방식.
1. 임베디드 방식 denormalized relationship


임베디드 방식 유저와 어드레스 문서를 연계시켜서 검색할 필요 없이 싱글 문서 하나에 모든 정보가 다 들어 있고 질의할 때에 편하다.
문제는 drawback인데 임베디드 이기 때문에 만약 톰에 주소가 100개라면 주소 배열 항목이 100개가 들어가야 한다.
즉 크기가 자꾸 커지게 된다. 이는 read/write performance에 영향을 미치게 된다.
문서 하나가 read/write 하는 범위를 넘게 되면 한 번에 못 읽어오게 되고 여러 번 디스크를 읽어야 한다.
2. 참조 방식 normalized relationship
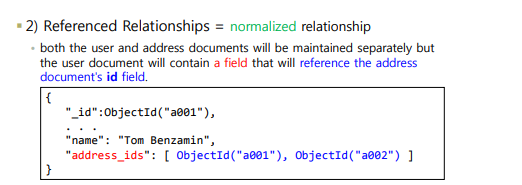
외래 키를 만들어서 표현하듯 몽고 db에서도 2개의 분리된 상태에서 표현할 수 있는데 referenced 한 방법 ( 관계형
db에서 많이 사용 )이다.
주소 문서가 직접 들어오지 않고 ID값만 끌고 들어온다. 즉 외래 키
임베디드 방식은 주소 자체가 임베디드 돼있기에 findOne 한 번이면 주소가 나온다.
하지만 참조 방식은 실제 주소를 가지고 있지 않고 참조하는 ID 값만 가진다. Tom에 주소를 검색하기 위해서
findOne을 2번 질의해야 한다.
1. 이름이 Tom인 주소를 검색해라 2. 주소만 모여있는 collection에 가서 ID 값이 a00인 문서 2개만 뽑기

임베디드 질의 
참조 질의 
result => {_id:ObjectId("u001"), address_ids" : [ObjectId("a001"), ObjectId("a002")}
db.address.find({"_id" : { "$in " : [ObjectId("a001"), ObjectId("a002")] }} )
가 돼야 된다.

이 2가지 이외에 몽고 DB만의 referenced 방법이 또 있다. reference에 대한 값을 일일이 손으로 넣어줘야
한다. 앞서 본 reference는 만약 Tom이 집을 하나 더 샀다면 주소 field를 업데이트해야 되는데 유저가 수작업으로 해주
어야 한다. 혹은 집을 팔은 경우, 따라서 이를 manual 방식이라 부른다. 하지만 서로 다른 컬렉션의 문서를 참조할 때 이 2
가지 외에 DBRef라는 표기법이 있다.
그렇다면 Manual References vs DBRefs를 알아보자.

manual 방식 : 일방적인 방법. 참조 성을 표현할 때 가장 무난하다.
DBRefs 방식 : 특별히 서로 다른 컬렉션에 들어있는 reference 방식을 표현하고자 할 때 쓸 수 있다.
이 방식은 형식이 정해져 있는데

users 변수에 문서가 답으로 들어와있다. ref , id, db 순서대로 나와야 한다. 참조하는 문서는 user col 참조되는 문서는 address col에 있다고 가정하자.
ref 참조되는 문서가 같은 컬렉션 인지
id는 ref 중에서도 현재 참조되는 id 값
db는 서로 다른 db에 있을 경우 참조하기 위해서는 db까지 알아야 한다. ( 옵션 )
혹시 참조하는 문서가 나와 다른 db에 있다면 db이름을 알려주어야 한다.
즉 서로 다른 컬렉션에 있을 때 쓰는 방식이다. manual 은 같은 컬렉션에 있는 경우 사용한다.
user.address 는 user문서에 address 필드 값만 빼주라는 소리이다. dbRef 변수에는 address 문서가
들어가 있다.
dbRef에 $ref니깐 값을 말한다 -> address_home
$id -> "$id": ObjectId("534009 e4 d852427820000002"),
- Covered Queries
원래 데이터는 디스크에 있고 디스크에 있는 데이터를 빠르게 접근하기 위해 인덱스를 통해
접근한다. 인덱스는 메모리에 존재하기 때문.
어떤 질의가 들어왔을 때 데이터까지 가지 않고 메모리에 있는 인덱스만을 이용해서 처리할 수 있는 방법이
Covered Queries이다

두 개의 field를 사용해서 인덱스를 만들었다. 남자 회원들에 이름을 다 찾아라.
gender 하고 name은 이미 인덱스 만들 때 사용한 field다 따라서 메인 메모리에 인덱스 자체에 gender 하고
name은 이미 올라와 있는 상태. 따라서 이런 질의가 들어온다면 index 내에서 다 해결이 가능하다.
디스크까지 갈 필요가 없음.

이러한 조건을 만족한다면
즉 질의에 사용한 field들이 인덱스 만들 때의 field여야 한다.
만약 프로젝션 쪽에 _id : 0을 빼먹었다면 인덱스에는 _id가 없으니 디스크까지 가야 된다.
따라서 covered queries를 만들 때는 _id 필드는 반드시 0으로 제외시켜 주어야 한다.
- Analyzing Queries 질의 분석
질의를 분석해주는 과정에서 도움을 받을 수 있는 몇 가지 연산자들
1. explain()

이 질의가 어떤 과정으로 처리되는지 어떤 인덱스가 쓰이는지 통계적인 정보들이 뜬다. 질의 최적 화기가 어떤
방법을 거쳐서 질의를 처리하는지 답만 말고 과정을 출력해준다.

explain 예 2. hint()

질의 최적화기는 인덱스 중 best solution을 통해 돌리는데 예를 들어 a, b, c 3개의
인덱스가 있고 explain()을 쓰면 b를 쓴다. 그런데 내가 생각하기에 a를 쓰게 되면 더 나을 것
같다는 생각을 한다. 이때 질의최적화기는 자기 판단에 의하여 b를 쓰게 되는데 a를 쓰면서 한번 처리해보고
싶다면 끝에다 .hint로 특정 인덱스로 처리하도록 강제화 시킬 수 있다.

=> 힌트로 질의를 처리했을때의 과정이 뜬다. 원래 방식과 비교해 볼 수 있다.
- Atomic Operations
db에 작업의 단위를 트랜젝션이라 한다. 트랜젝션은 처리가 될 때 acid로 처리돼야 되는데
이때 a는 atomic이다. 즉 분해되지 않아야 하는데 입금을 예로 되던지 안되던지로 여야지 조금 되거나
많이 되거나 해서는 안된다.
관계형db는 트랜젝션으로 모두 일처리를 한다. 따라서 질의를 던질 때 원자성이 모두 보장된다.
그런데 MongoDb는 원자성을 보장되지 않는다. 빠른 질의가 목표이므로.
하지만 제공은 하는데 오직 single document 단일 문서 에서만 제공한다. 즉 임베디드 방식으로 모든 관련된
문서를 싱글 문서에 집어넣는다면 원자적인 연산을 몽고 db가 보증해줄 수 있다.

잔고를 예로
v <- b
v <- v -50
b <- v 로 인출 트렌젝션이 구성된다.
그런데 잔고는 동시에 두 명이 들어갈 수 없다. 이 때 인출과 입금이 한 번씩 이루어진다고 하자.
v <- v -50 까지 즉 2단계까지 인출이 진행됐다고 하자.
이때 입금은
v <- b
v <- v + 50
b <- v인데 동시에 일어난다면 인출 2단계에서 멈추고 입금이 끝났다고 해보자. 그렇다면
처음 돈100에서 150이 되고 // 인출 3단계에서 v는 50이니 결과적으로 50이 돼버리는 것
즉 이렇게 단계를 쪼갤 수 없다. 이러한 atomic한 형태를 관계형 db에서는 보장해준다는 것
mongoDB에서는 원자성을 보장해주지 않으니 update 시 문제가 될 수 있다.
예를 들어보자
고객은 삼성 s3를 원한다.
product_available이 1이라고 생각해보자. a점에서 타이핑이 느린 이 사람은 결제부터 해버렸다.
이제 available를 줄이고 bought_by를 추가시켜주어야 한다.
이때 b점에서 타이핑이 매우 빠른 사람이 결제를 해버리고 insert를 시켜버렸다.
그 후 a점에서 문서를 삽입시켰다. 즉 -1이 되버리니 insert가 안될 것. 이 문제는 find와 insert
를 따로따로 했기에 일어나는 문제였다.
하지만 findAndModify로 던진다면 이런식으로 던질 수가 있다.

query가 0이상일때 넣는 것. 이 fAM은 원자성을 보장한다. 아무리 타이핑이 느려도 출발과 도착 사이에는
누구도 끼어 들수 없다.
- Advanced Indexing
이미 배운것 들이다.

태그에 field값은 배열이다. field에 값이 배열인 경우 생성되는 인덱스를 멀티키 인덱스가 자동으로 생성된다.

서브 문서를 필드값으로 갖는 경우. 서브문서에 있는 키들을 하나하나 빼서 인덱싱 해주면 된다.
'DB > MongoDB 정리' 카테고리의 다른 글
mongoDB 튜토리얼 7. 샤딩 (0) 2019.11.26 mongoDB 튜토리얼 6. 레플리카 셋 (0) 2019.11.19 MongoDB 튜토리얼 5. Aggregation (0) 2019.10.15 MongoDB 튜토리얼 4. CRUD (31) 2019.10.01 MongoDB 튜토리얼 3. CRUD (31) 2019.09.24